

Overview
17.1 Introduction
to Static Routing
17.1.1
Introduction to routing
17.1.2 Static
route operation
17.1.3
Configuring static routes
17.1.4
Configuring default route forwarding
17.1.5 Verifying static
route configuration
17.1.6
Troubleshooting static route configuration
17.2 Dynamic
Routing Overview
17.2.1
Introduction to routing protocols
17.2.2 Autonomous
systems
17.2.3 Purpose of
a routing protocol and autonomous systems
17.2.4 Identifying
the classes of routing protocols
17.2.5 Distance
vector routing protocol features
17.2.6 Link-state
routing protocol features
17.3 Routing
Protocols Overview
17.3.1 Path
determination
17.3.2 Routing
configuration
17.3.3 Routing
protocols
17.3.4 IGP versus
EGP
Summary
Overview
Routing is a set
of directions to get from one network to another. These directions, also known
as routes, can be dynamically given to the router by another router, or they
can be statically assigned to the router by an administrator.
This module
introduces the concept of dynamic routing protocols, describes the classes of
dynamic routing protocols, and gives examples of protocols in each class.
A network
administrator chooses a dynamic routing protocol based upon many
considerations. These include the size of the network, the bandwidth of
available links, the processing power of the routers, the brands and models of
the routers, and the protocols that are used in the network. This module will
provide more details about the differences between routing protocols that help
network administrators make a choice.
This module
covers some of the objectives for the CCNA 640-801, INTRO 640-821, and ICND
640-811 exams. -
Students who
complete this module should be able to perform the following tasks:
- Explain the significance of
static routing
- Configure static and default
routes
- Verify and troubleshoot static
and default routes
- Identify the classes of routing
protocols
- Identify distance vector
routing protocols
- Identify link-state routing
protocols
- Describe the basic
characteristics of common routing protocols
- Identify interior gateway
protocols
- Identify exterior gateway
protocols
- Enable Routing Information
Protocol (RIP) on a router
17.1
Introduction to Static Routing
17.1.1
Introduction to routing
This page will
describe routing and explain the differences between static and dynamic
routing.
Routing is the
process that a router uses to forward packets toward the destination network. A
router makes decisions based upon the destination IP address of a packet. All
devices along the way use the destination IP address to send the packet in the
right direction to reach its destination. To make the correct decisions,
routers must learn how to reach remote networks. When routers use dynamic
routing, this information is learned from other routers. When static routing is
used, a network administrator configures information about remote networks
manually.
Since static
routes are configured manually, network administrators must add and delete
static routes to reflect any network topology changes. In a large network, the
manual maintenance of routing tables could require a lot of administrative
time. On small networks with few possible changes, static routes require very
little maintenance. Static routing is not as scalable as dynamic routing
because of the extra administrative requirements. Even in large networks,
static routes that are intended to accomplish a specific purpose are often
configured in conjunction with a dynamic routing protocol.
17.1
Introduction to Static Routing
17.1.2
Static route operation
This page will
explain how static routes operate and how they are created.
Static route
operations can be divided into these three parts:
- Network administrator
configures the route
- Router installs the route in
the routing table
- The static route is used to
route packets.
An administrator
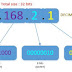
must use the ip route command to manually configure a static route. The correct
syntax for the ip route command is shown in Figure .
In Figures and , the network administrator of the
Hoboken router needs to configure a static route to the 172.16.1.0/24 and
172.16.5.0/24 networks on the other routers. The administrator could enter
either of two commands to accomplish this objective. The method in Figure specifies the outgoing interface. The method
in Figure specifies the next-hop IP
address of the adjacent router. Either of the commands will install a static
route in the routing table of Hoboken.
The
administrative distance is an optional parameter that indicates the reliability
of a route. A lower value for the administrative distance indicates a more
reliable route. A route with a lower administrative distance will be installed
before a similar route with a higher administrative distance. The default
administrative distance when using a static route is 1. When an outbound
interface is configured as the gateway in a static route, the static route will
be shown in the routing table as being directly connected. This is sometimes
confusing, since a true directly connected route has an administrative distance
of 0. To verify the administrative distance of a particular route, use the show
ip routeaddress command, where the ip address of the particular route is
inserted for the address option. If an administrative distance other than the
default is desired, a value between 0 and 255 is entered after the next-hop or
outgoing interface as follows:
waycross(config)#ip
route 172.16.3.0 255.255.255.0 172.16.4.1 130
If the router
cannot reach the outgoing interface that is being used in a route, the route
will not be installed in the routing table. This means if that interface is
down, the route will not be placed in the routing table.
Sometimes static
routes are used for backup purposes. A static route can be configured on a
router that will only be used when the dynamically learned route has failed. To
use a static route as a backup, set a higher administrative distance than the
dynamic routing protocol.
17.1
Introduction to Static Routing
17.1.3
Configuring static routes
This page lists
the steps used to configure static routes and gives an example of a simple
network for which static routes might be configured.
Use the following
steps to configure static routes:
Step 1 Determine
all desired prefixes, masks, and addresses. The address can be either a local
interface or a next hop address that leads to the desired destination.
Step 2 Enter
global configuration mode.
Step 3 Type the
ip route command with a prefix and mask followed by the corresponding address
from Step 1. The administrative distance is optional.
Step 4 Repeat
Step 3 for all the destination networks that were defined in Step 1.
Step 5 Exit
global configuration mode.
Step 6 Use the
copy running-config startup-config command to save the active configuration to
NVRAM.
The example
network is a simple three-router configuration.
Hoboken must be configured so that it can reach the 172.16.1.0 network
and the 172.16.5.0 network. Both of these networks have a subnet mask of
255.255.255.0.
Packets that have
a destination network of 172.16.1.0 need to be routed to Sterling and packets
that have a destination address of 172.16.5.0 need to be routed to Waycross.
Static routes can be configured to accomplish this task.
Both static
routes will first be configured to use a local interface as the gateway to the
destination networks. Since the
administrative distance was not specified, it will default to 1 when the route
is installed in the routing table.
The same two
static routes can also be configured with a next-hop address as their
gateway. The first route to the
172.16.1.0 network has a gateway of 172.16.2.1. The second route to the
172.16.5.0 network has a gateway of 172.16.4.2. Since the administrative
distance was not specified, it defaults to 1.
17.1
Introduction to Static Routing
17.1.4
Configuring default route forwarding
This page will
show students how to configure default static routes.
Default routes
are used to route packets with destinations that do not match any of the other
routes in the routing table. Routers are typically configured with a default
route for Internet-bound traffic, since it is often impractical and unnecessary
to maintain routes to all networks in the Internet. A default route is actually
a special static route that uses this format:
ip route 0.0.0.0
0.0.0.0 [next-hop-address | outgoing interface ]
The 0.0.0.0 mask,
when logically ANDed to the destination IP address of the packet to be routed,
will always yield the network 0.0.0.0. If the packet does not match a more
specific route in the routing table, it will be routed to the 0.0.0.0 network.
Use the following
steps to configure default routes:
Step 1 Enter global
configuration mode.
Step 2 Type the
ip route command with 0.0.0.0 for the prefix and 0.0.0.0 for the mask. The
address option for the default route can be either the local router interface
that connects to the outside networks or the IP address of the next-hop router.
Step 3 Exit
global configuration mode.
Step 4 Use the
copy running-config startup-config command to save the active configuration to
NVRAM.
On the previous
page, static routes were configured on Hoboken to access networks 172.16.1.0 on
Sterling and 172.16.5.0 on Waycross. It should now be possible to route packets
to both of these networks from Hoboken. However, Sterling and Waycross will not
know how to return packets to any network that is not directly connected. A
static route could be configured on Sterling and Waycross for each of these
destination networks. This would not be a scalable solution on a larger
network.
Sterling connects
to all networks that are not directly connected through interface Serial 0.
Waycross has only one connection to all non-directly connected networks. This
is through interface Serial 1. A default route on Sterling and Waycross will be
used to route all packets that are destined for networks that are not directly
connected.
17.1
Introduction to Static Routing
17.1.5
Verifying static route configuration
This page will
teach students the process that is used to verify static route configurations.
After static
routes are configured it is important to verify that they are present in the routing
table and that routing is working as expected. The command show running-config
is used to view the active configuration in RAM to verify that the static route
was entered correctly. The show ip route
command is used to make sure that the static route is present in the routing
table.
Use the following
steps to verify static route configuration:
- Enter the show running-config
command in privileged mode to view the active configuration.
- Verify that the static route
has been correctly entered. If the route is not correct, it will be
necessary to go back into global configuration mode to remove the
incorrect static route and enter the correct one.
- Enter the command show ip
route.
- Verify that the route that was
configured is in the routing table.
17.1
Introduction to Static Routing
17.1.6
Troubleshooting static route configuration
This page will
show students how to troubleshoot a static route configuration.
On an earlier
page, students configured static routes on Hoboken to access networks on
Sterling and Waycross. In this
configuration, nodes on the Sterling 172.16.1.0 network cannot reach nodes on
the Waycross 172.16.5.0 network.
From privileged
EXEC mode on the Sterling router, ping to a node on the 172.16.5.0
network. The ping fails. Now use the
traceroute command from Sterling to the address that was used in the ping
statement. Note where the traceroute
fails. The traceroute indicates that the ICMP packet was returned from Hoboken
but not from Waycross. This implies that the trouble exists either on Hoboken
or Waycross.
Telnet to the
Hoboken router. Try again to ping the node on the 172.16.5.0 network connected
to the Waycross router. This ping should
succeed because Hoboken is directly connected to Waycross.
17.2
Dynamic Routing Overview
17.2.1
Introduction to routing protocols
This page will
introduce routing protocols and how they are used.
Routing protocols
are different from routed protocols in both function and task.
A routing
protocol is the communication used between routers. A routing protocol allows
routers to share information about networks and their proximity to each other.
Routers use this information to build and maintain routing tables.
Examples of
routing protocols are as follows:
- Routing Information Protocol
(RIP)
- Interior Gateway Routing
Protocol (IGRP)
- Enhanced Interior Gateway
Routing Protocol (EIGRP)
- Open Shortest Path First (OSPF)
A routed protocol
is used to direct user traffic. A routed protocol provides enough information in
its network layer address to allow a packet to be forwarded from one host to
another based on the addressing scheme.
Examples of
routed protocols are as follows:
- Internet Protocol (IP)
- Internetwork Packet Exchange
(IPX)
17.2
Dynamic Routing Overview
17.2.2
Autonomous systems
This page will
define an autonomous system (AS).
An AS is a
collection of networks under a common administration that share a common
routing strategy. To the outside world, an AS is viewed as a single entity. The
AS may be run by one or more operators while it presents a consistent view of
routing to the external world.
The American
Registry of Internet Numbers (ARIN), a service provider, or an administrator
assigns a 16-bit identification number to each AS. This autonomous system
number is a 16 bit number. Routing protocols, such as Cisco IGRP, require the
assignment of a unique, AS number.
17.2
Dynamic Routing Overview
17.2.3
Purpose of a routing protocol and autonomous systems
This page will explain
why routing protocols and autonomous systems are used.
The goal of a
routing protocol is to build and maintain a routing table. This table contains
the learned networks and associated ports for those networks. Routers use
routing protocols to manage information received from other routers and its
interfaces, as well as manually configured routes.
The routing
protocol learns all available routes, places the best routes into the routing
table, and removes routes when they are no longer valid. The router uses the
information in the routing table to forward routed protocol packets.
The routing
algorithm is fundamental to dynamic routing. Whenever the topology of a network
changes because of growth, reconfiguration, or failure, the network
knowledgebase must also change. The network knowledgebase needs to reflect an
accurate view of the new topology.
When all routers
in an internetwork operate with the same knowledge, the internetwork is said to
have converged. Fast convergence is desirable because it reduces the period of
time in which routers would continue to make incorrect routing decisions.
Autonomous
systems divide the global internetwork into smaller and more manageable
networks. Each AS has its own set of rules and policies and an AS number that
will distinguish it from all other autonomous systems.
17.2
Dynamic Routing Overview
17.2.4
Identifying the classes of routing protocols
This page will
introduce two classes of routing protocols. Students will also learn the
differences between them.
Most routing
algorithms can be classified into one of two categories:
Distance vector
Link-state
The distance
vector routing approach determines the direction, or vector, and distance to
any link in an internetwork. The link-state approach recreates the exact
topology of an entire internetwork.
17.2
Dynamic Routing Overview
17.2.5
Distance vector routing protocol features
This page will
explain how the distance vector routing protocol is used.
The distance
vector routing algorithm passes periodic copies of a routing table from router
to router. These regular updates between routers communicate topology changes.
The distance vector routing algorithm is also known as the Bellman-Ford
algorithm.
Each router
receives a routing table from its directly connected neighbor routers. Router B receives information from Router A.
Router B adds a distance vector number, such as a number of hops. This number
increases the distance vector. Then Router B passes this new routing table to
its other neighbor, Router C. This same step-by-step process occurs in all
directions between neighbor routers.
The algorithm
eventually accumulates network distances so that it can maintain a database of
network topology information. However, the distance vector algorithm does not
allow a router to know the exact topology of an internetwork since each router
only sees its neighbor routers.
Each router that
uses distance vector routing first identifies its neighbors. The interface that leads to each directly
connected network has a distance of 0. As the distance vector discovery process
proceeds, routers discover the best path to destination networks based on the
information they receive from each neighbor. Router A learns about other
networks based on the information that it receives from Router B. Each of the
other network entries in the routing table has an accumulated distance vector
to show how far away that network is in a given direction.
Routing table
updates occur when the topology changes. As with the network discovery process,
topology change updates proceed step-by-step from router to router. Distance vector algorithms call for each
router to send its entire routing table to each of its adjacent neighbors. The
routing tables include information about the total path cost as defined by its
metric and the logical address of the first router on the path to each network
contained in the table.
An analogy of
distance vector could be the signs found at a highway intersection. A sign
points toward a destination and indicates the distance to the destination.
Further down the highway, another sign points toward the destination, but now
the distance is shorter. As long as the distance is shorter, the traffic is on
the best path.
17.2
Dynamic Routing Overview
17.2.6
Link-state routing protocol features
The other basic
algorithm that is used for routing is the link-state algorithm. This page will
explain how the link-state algorithm works.
The link-state
algorithm is also known as Dijkstra's algorithm or as the shortest path first
(SPF) algorithm. The link-state routing algorithm maintains a complex database
of topology information. The distance vector algorithm has nonspecific
information about distant networks and no knowledge of distant routers. The
link-state routing algorithm maintains full knowledge of distant routers and
how they interconnect.
Link-state
routing uses the following features:
- Link-state advertisement (LSA)
- a small packet of routing information that is sent between routers
- Topological database - a
collection of information gathered from LSAs
- SPF algorithm - a calculation
performed on the database that results in the SPF tree
- Routing table - a list of the
known paths and interfaces
Network discovery
processes for link state routing
When routers
exchange LSAs, they begin with directly connected networks for which they have
information. Each router constructs a topological database that consists of all
the exchanged LSAs.
The SPF algorithm
computes network reachability. The router constructs this logical topology as a
tree, with itself as the root. This topology consists of all possible paths to
each network in the link-state protocol internetwork. The router then uses SPF
to sort these paths. The router lists the best paths and the interfaces to
these destination networks in the routing table. It also maintains other
databases of topology elements and status details.
The first router
that learns of a link-state topology change forwards the information so that
all other routers can use it for updates.
Common routing information is sent to all routers in the internetwork.
To achieve convergence, each router learns about its neighbor routers. This
includes the name of each neighbor router, the interface status, and the cost
of the link to the neighbor. The router constructs an LSA packet that lists
this information along with new neighbors, changes in link costs, and links
that are no longer valid. The LSA packet is then sent out so that all other
routers receive it.
When a router
receives an LSA, it updates the routing table with the most recent information.
The accumulated data is used to create a map of the internetwork and the SPF
algorithm is used to calculate the shortest path to other networks. Each time
an LSA packet causes a change to the link-state database, SPF recalculates the
best paths and updates the routing table.
There are three
main concerns related to link-state protocols:
- Processor overhead
- Memory requirements
- Bandwidth consumption
Routers that use
link-state protocols require more memory and process more data than routers
that use distance vector routing protocols. Link-state routers need enough
memory to hold all of the information from the various databases, the topology
tree, and the routing table. Initial
link-state packet flooding consumes bandwidth. In the initial discovery
process, all routers that use link-state routing protocols send LSA packets to
all other routers. This action floods the internetwork and temporarily reduces
the bandwidth available for routed traffic that carries user data. After this
initial flooding, link-state routing protocols generally require minimal
bandwidth to send infrequent or event-triggered LSA packets that reflect
topology changes.
17.3
Routing Protocols Overview
17.3.1
Path determination
This page will
explain how a router determines the path of a packet from one data link to
another. The router uses two basic functions:
- A path determination function
- A switching function
Path determination
occurs at the network layer. The path determination function enables a router
to evaluate the paths to a destination and to establish the preferred way to
handle a packet. The router uses the routing table to determine the best path
and then uses the switching function to forward the packet. -
The switching
function is the internal process used by a router to accept a packet on one
interface and forward it to a second interface on the same router. A key
responsibility of the switching function of the router is to encapsulate
packets in the appropriate frame type for the next data link.
Figure illustrates how routers use addressing for
these routing and switching functions. The router uses the network portion of
the address to make path selections to pass the packet to the next router along
the path.
17.3
Routing Protocols Overview
17.3.2
Routing configuration
This page will
explain the steps that are used to configure a routing protocol.
To enable an IP
routing protocol on a router, global and routing parameters need to be set.
Global tasks include the selection of a routing protocol such as RIP, IGRP,
EIGRP, or OSPF. The major task in the routing configuration mode is to indicate
IP network numbers. Dynamic routing uses broadcasts and multicasts to
communicate with other routers.
The router
command starts a routing process.
The network
command enables the routing process to determine which interfaces send and
receive routing updates.
An example of a
routing configuration is as follows:
GAD(config)#router
rip
GAD(config-router)#network
172.16.0.0
For RIP and IGRP,
the network numbers are based on the network class addresses, not subnet
addresses or individual host addresses.
17.3 Routing Protocols Overview
17.3.3 Routing protocols
This page will
give some examples of routing protocols and how they are used.
At the Internet
layer of the TCP/IP suite of protocols, a router can use an IP routing protocol
to accomplish routing through the implementation of a specific routing
algorithm. Examples of IP routing protocols include the following:
- RIP - a distance vector
interior routing protocol
- IGRP - the Cisco distance
vector interior routing protocol
- OSPF - a link-state interior
routing protocol
- EIGRP - the advanced Cisco
distance vector interior routing protocol
- BGP - a distance vector
exterior routing protocol
RIP was
originally specified in RFC 1058. Its key characteristics include the
following:
- It is a distance vector routing
protocol.
- Hop count is used as the metric
for path selection.
- If the hop count is greater
than 15, the packet is discarded.
- Routing updates are broadcast
every 30 seconds, by default.
IGRP is a
proprietary protocol developed by Cisco. Some of the IGRP key design
characteristics are as follows:
- It is a distance vector routing
protocol.
- Bandwidth, load, delay and
reliability are used to create a composite metric.
- Routing updates are broadcast
every 90 seconds, by default.
OSPF is a
nonproprietary link-state routing protocol.
- It is a link-state routing
protocol.
- It is an open standard routing
protocol described in RFC 2328.
- The SPF algorithm is used to
calculate the lowest cost to a destination.
- Routing updates are flooded as
topology changes occur.
EIGRP is a Cisco
proprietary enhanced distance vector routing protocol. The key characteristics
of EIGRP are as follows:
- It is an enhanced distance
vector routing protocol.
- It uses unequal cost load
balancing.
- It uses a combination of
distance vector and link-state features.
- It uses Diffusing Update
Algorithm (DUAL) to calculate the shortest path.
- Routing updates are multicast
using 224.0.0.10 triggered by topology changes.
Border Gateway
Protocol (BGP) is an exterior routing protocol. The key characteristics of BGP
are as follows:
- It is a distance vector
exterior routing protocol.
- It is used between ISPs or ISPs
and clients.
- It is used to route Internet
traffic between autonomous systems.
17.3
Routing Protocols Overview
17.3.4
IGP versus EGP
This page will
help students understand the differences between interior and exterior routing
protocols.
Interior routing
protocols are designed for use in a network that is controlled by a single
organization. The design criteria for an interior routing protocol require it
to find the best path through the network. In other words, the metric and how
that metric is used is the most important element in an interior routing
protocol.
An exterior
routing protocol is designed for use between two different networks that are
under the control of two different organizations. These are typically used
between ISPs or between a company and an ISP. For example, a company would run
BGP, an exterior routing protocol, between one of its routers and a router
inside an ISP. IP exterior gateway protocols require the following three sets
of information before routing can begin:
- A list of neighbor routers with
which to exchange routing information
- A list of networks to advertise
as directly reachable
- The autonomous system number of
the local router
An exterior
routing protocol must isolate autonomous systems. Remember, autonomous systems
are managed by different administrations. Networks must have a protocol to
communicate between these different systems.
Each AS must have
a 16-bit identification number, which is assigned by ARIN or a provider, to use
routing protocols such as IGRP and EIGRP.
Summary
This page
summarizes the topics discussed in this module.
The process that
a router uses to forward packets toward the destination network is called
routing. Decisions are based upon the destination IP address of each packet.
When routers use dynamic routing, they learn about remote networks from other
routers. When static routing is used, a network administrator configures information
about remote networks manually.
Static route
operations can be divided into these three parts. First a network administrator
uses the ip route command to configure a static route. Then the router installs
the route in the routing table. Finally, the route is used to route packets.
Static routes can
be used for backup purposes. A static route can be configured on a router that
will only be used when the dynamically learned route has failed.
After static
routes are configured, verify they are present in the routing table and that
routing works as expected. Use the command show running-config to view the
active configuration in RAM. The show ip route command is used to make sure
that the static route is present in the routing table.
The communication
used between routers is referred to as a routing protocol. The goal of a
routing protocol is to build and maintain the routing table.
A routed protocol
is used to direct user traffic. A routed protocol provides enough information
in its network layer address to allow a packet to be forwarded from one host to
another based on the addressing scheme.
An AS is a
collection of networks under the same administration that share a common
routing strategy. Autonomous systems divide the global internetwork into
smaller and more manageable networks. Each AS has its own set of rules and
policies and a number that distinguishes it from all other autonomous systems.
The distance
vector routing approach determines the direction, or vector, and distance to
any link in an internetwork. The link-state approach recreates the exact
topology of an entire internetwork.
Distance vector
routing algorithms pass periodic copies of a routing table from router to
router. These regular updates between routers communicate topology changes. The
distance vector routing algorithm is also known as the Bellman-Ford algorithm.
The second basic
algorithm used for routing is the link-state algorithm. The link-state
algorithm is also known as the Dijkstra algorithm or as the SPF algorithm.
Link-state routing algorithms maintain a complex database of topology
information. The distance vector algorithm has nonspecific information about
distant networks and no knowledge of distant routers. A link-state routing
algorithm maintains full knowledge of distant routers and how they
interconnect.
Interior routing
protocols are designed for use in a network whose parts are under the control
of a single organization. An exterior routing protocol is designed for use
between two different networks that are under the control of two different
organizations. These are typically used between ISPs or between a company and
an ISP.



No comments:
Post a Comment